Error Handling Patterns You Can Follow in Your Applications with Apache Kafka
Creating a “retry-topic” is the first thing you should do to skip errors (which can be resolved when a condition is met or via an external intervention) without halting the whole process and keeping related data in a separate queue for further inspection or retry flow. Now, you can route events that result in an exception during processing to that queue.
However, if the error is not ever possible to solve via a retry process (such as a never ever unhandled case, maybe a corrupt field value, e.g.), you should create an “error topic” which is called a “dead-letter queue”.
Now that you have a “retry-topic”, you should have a corresponding retry application (or a service) which will be responsible for the retry process. This will be the place where the events will wait until the required conditions are met and then will be processed (waiting until a particular parameter value required for the process is inserted in a database, e.g.).
Please follow the numbers on top of the arrows on the diagram below:

However, there will certainly be cases where the process order of events is crucial. If we need to maintain the order (for example, inventory stock increase/decrease or card credit/debit transactions must be kept in order), the main application should group and keep track of events that are routed to the “retry-topic”.
In the main application, we should create an “event group” structure and assign a unique identifier to that group. The “unique group id” and its grouped events’ ids should be kept in an in-memory structure.
So, assume that event B arrives after event A is sent to the “retry-topic” and it is a must that we process event A first and then event B. What we should do when event B arrives is that we should send event B directly to the “retry-topic” (as well as updating the “event group” info resting in the in-memory structure) without processing. To preserve the order in the “retry-topic”, we should add a header with the value of the group unique id when we route the event to the topic.
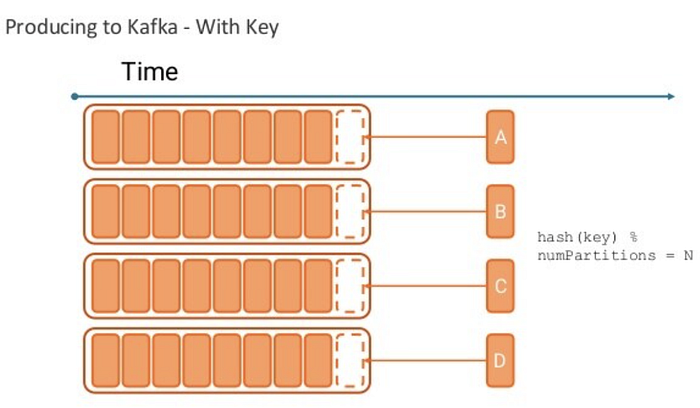
In Kafka, it is possible to have producers add a “key” to a message — all messages with the same key will go to the same partition. While messages are added and stored within partitions in sequence, messages without keys are written to partitions in a round robin fashion.

By leveraging keys, you can guarantee the order of processing for messages in Kafka that share the same key.
We should also create a “redirect topic” where we will be sending the “unique event id” value (only the unique “event” id value, generated with or including the unique “group” id value — without any other related event info).
When the retry application handles an event in the retry topic successfully (and then after that, maybe publishes to the target topic), it also publishes confirmation in the form of a “tombstone event” to the redirect topic. One tombstone event is published for each successfully retried event.
In Kafka, a record with the same key from the record we want to delete is produced to the same topic and partition with a null payload. These records are called tombstones.
It is the main application that listens to the “redirect topic” for “tombstone events” that signal successful retry. The main application removes the messages (one by one after they are finished with retry processing) from the in-memory store. As soon as there are no related events left in the in-memory structure, the subsequent events for the same item continues to be processed through the main flow.
In the case of a failure in the in-memory store, data can easily be restored by reading the unique event ids in the “redirect topic” and initializing that in-memory store. Since we have included the “unique group id” value in the “unique event id” generation process, we can use the group id to gather event ids back in a group data format.
Please follow the numbers on top of the arrows on the diagram below:

To sum up all, besides our main application, we need an error topic, a retry topic, a retry application and a redirect topic for error handling with Kafka.
Happy Coding!
